RDM kalauz
Mi a kutatási adat?
A kutatási adatok a tudományos közösség által létrehozott, rögzített, elfogadott és megőrzött tényadatok, amelyek a kutatási eredmények hitelességét támasztják alá. Létrejöhetnek megfigyelések, kísérletek, szimulációk eredményeképpen – ekkor beszélhetünk nyers kutatási adatokról – vagy korábban gyűjtött adatok összegyűjtésével, válogatásával, feldolgozásával.
A Research Data Management (RDM) összefoglaló kifejezést használjuk a kutatási adatokkal kapcsolatos tevékenységek leírására, magyarul pedig a kutatási adatok kezelése (ill. kutatási adatkezelés, kutatási adatmenedzsment) kifejezéseket használják a terület megnevezésére.
A kutatási adatok típusairól bővebben a https://openscience.hu/kutatasi-adatok oldalon olvashat.
A kutatási adatok életciklusa (Research Data Lifecycle)
A kutatási adatok életciklusának leírására többféle modell létezik, melyek között általában nagy az átfedés, részletességükben viszont eltérőek lehetnek. Egyiknek sem az a célja, hogy előírja, a kutatási adatoknak milyen fázisokon kell átesniük, hanem az, hogy minél átfogóbban, valósághűen leírják, hogyan viselkednek, milyen lépések történnek az adatokkal a kutatás során. Azért érdemes ismerni ezeket a modelleket, hogy a kutatási adatokat minél jobban ki- és fel tudjuk használni, illetve megértsük, hogyan lenne legcélszerűbb saját kutatási adatainkat kezelni.
Az alábbiakban két példát mutatunk be a kutatási adatok életciklusának leírására: az egyik ciklikusan (Data One Data Lifecycle), a másik egymásra épülő rétegekként (Digital Curation Centre Curation Lifecycle Model) illusztrálja ezt a folyamatot.
Data One Data Lifecycle:
https://old.dataone.org/data-life-cycle

- Tervezés: az összegyűjteni vagy létrehozni kívánt adatok leírása, kezelésüknek és elérhetővé tételüknek meghatározása = adatkezelési terv készítése
- Adatgyűjtés: a tervezés során meghatározott adatok begyűjtése (különböző eszközökkel) és rögzítése valamilyen formában (lehetőleg digitálisan)
- Minőségbiztosítás: a rögzített adatok minőségének ellenőrzése
- Leírás: az adatok pontos és alapos leírása a megfelelő metaadat-szabványok segítségével
- Megőrzés: az adatok elhelyezése egy számukra megfelelő, megbízható, hosszútávú archiválást biztosító tárhelyre (pl. adatrepozitórium)
- Feltérképezés: potenciálisan hasznosítható adatok keresése és megszerzése, a leíró információkkal (meta-adatokkal) együtt
- Integráció: a különböző forrásokból származó adatok összefűzése egyetlen, egységes adathalmazzá, amely már alkalmas az elemzésre
- Elemzés: az összegyűjtött és rendszerezett adatok elemzése, vizsgálata
Fontos megjegyezni, hogy a kutatási adatok életciklusának egyes fázisai nem feltétlen ebben a meghatározott sorrendben követik egymást. Az is gyakran előfordul, hogy a kutatási folyamat során egy-egy lépés hiányzik, míg mások akár többször is megismétlődnek.
Digital Curation Centre Curation Lifecycle Model:
https://www.dcc.ac.uk/sites/default/files/documents/publications/DCCLifecycle.pdf
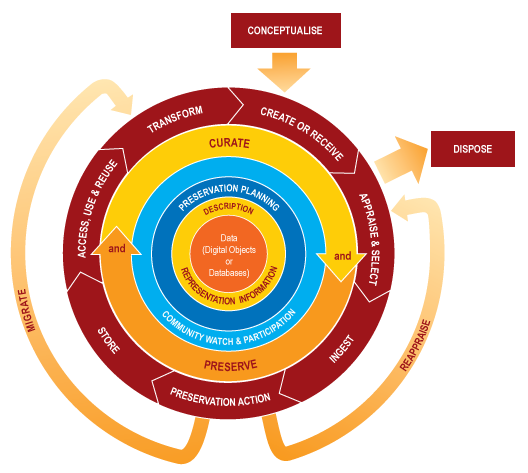
A DCC Curation Lifecycle modell középpontjában a nyers és már strukturált kutatási adatok, illetve ezek metaadatai állnak. Ezekre épülnek olyan elsődleges, az adatok életciklusának egészét meghatározó alapvető tevékenységek, mint
- a leíró metaadatok megadása
- az adatok tárolásának és adminisztrációjának megtervezése
- a kutatóközösség normáinak való megfeleltetése
- végül a hosszú távú megőrzés biztosítása.
Az ábrán látható piros kör illusztrálja azokat az egymást követő lépéseket, amik a kutatási adatokkal kapcsolatban fontosak lehetnek, úgymint
- az adatgyűjtés és -tárolás módjának megtervezése
- adatok létrehozása vagy begyűjtése
- adminisztratív, leíró és technikai jellegű metaadatok létrehozása
- a megőrzendő adatok kiválasztása az adathalmazból, és ezek elhelyezése a választott tárhelyen
- a hosszú távú megőrzés és adatminőség biztosítása (adattisztítás, fájlformátumok, adatszerkezet ellenőrzése)
- az adatok biztonságos archiválása
- az adatokhoz való hozzáférés biztosítása és szükség szerinti szabályozása
- új adathalmazok létrehozása a meglévő adatok transzformációjával.
Az eddigiekhez kapcsolódik még néhány, alkalomszerűen végzett tevékenység, például
- ha a kutatás során keletkezett olyan adat, ami végül nem lett felhasználva, gondoskodni kell annak archiválásáról is
- ha maradt olyan adat, amit a jövőben sem lehet majd felhasználni, akkor gondoskodni kell annak biztonságos megsemmisítéséről
- ha nem értékelhető, vagy nem megfelelő adat keletkezett, azt újra meg kell vizsgálni
- amennyiben szükséges, migrálni kell az adatokat (pl. másik tárhelyre vagy fájlformátumba).
Gyakorlati tudnivalók
A kutatási adatok kezelésének számos jó gyakorlata van, melyek követésével rengeteg idő és energia takarítható meg. Igyekeztünk összegyűjteni a legalapvetőbb praktikákat, melyek segítségével egyszerűen és hatékonyan menedzselhetjük kutatási adatainkat.
Fájlnevek és verziózás
A fájlok könnyű visszakereshetősége és rendszerezhetősége érdekében ajánlott egyezményes, informatív és egyértelmű fájlneveket alkalmazni. Ha csak egy ember foglalkozik az adott fájlokkal, akkor sem biztos, hogy 1-2 év elteltével emlékezni fog, milyen adatot tartalmaz egy fájl – ez a probléma a kutatásban résztvevők számával egyenes arányban nő. Csoportos kutatások esetén különösen fontos a következetesség, és hogy minden résztvevő ugyanazt a fájl-elnevezési gyakorlatot kövesse.
A következő jó gyakorlatokkal rengeteg idő és kellemetlenség spórolható meg:
- a fájlnév maximum 32 karakter hosszú legyen
- ne tartalmazzon speciális karaktereket (pl.: . , -) és szóközt, elválasztásra a _ karaktert alkalmazzuk
- minden, az azonosításhoz szükséges információt tartalmaznia kell, pl.: melyik kutatáshoz kapcsolódik, a kutatás melyik részéhez kapcsolódik, ki készítette, mikor jött létre a fájl, nyelvi információ, stb.
- a fájlnév végén jelöljük a verziót, pl. name_date_v02.png
- sorszámozás esetén használjunk azonos helyiértékeket, pl. 001, 034, 215
- ne használjunk túl általános fájlneveket (pl. grafikon), mert a fájl esetleges áthelyezésekor könnyen előfordulhat, hogy ütközni fog más, ugyanilyen nevű fájlokkal
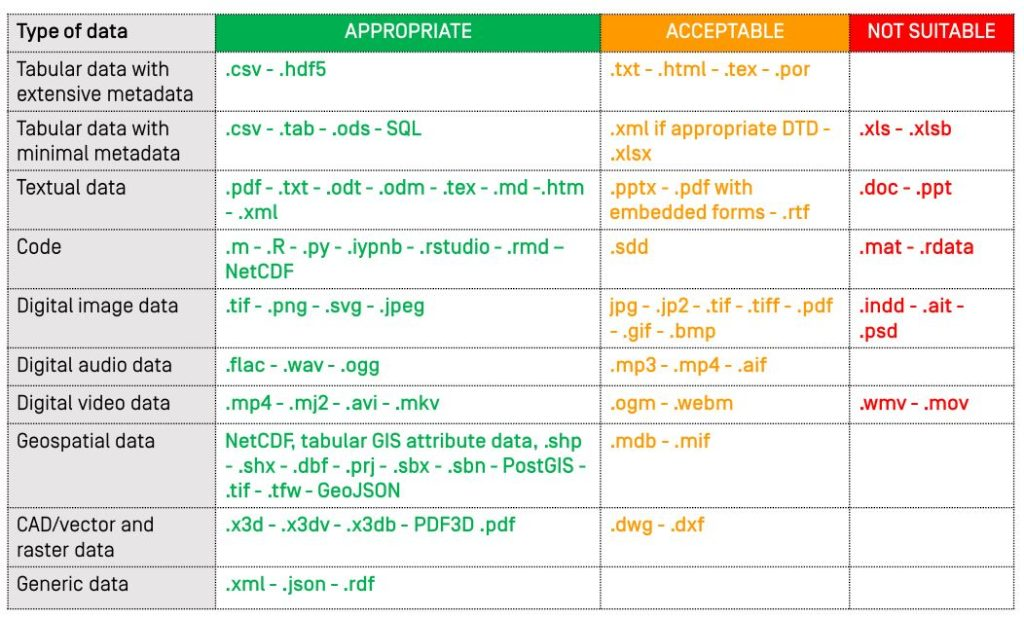
Fájlformátumok
Amennyiben lehetőség van rá, törekedjünk a szoftver-független formátumok használatára, így biztosíthatjuk a fájlok mobilitását és egyszerűbb megosztását. Egyes esetekben hasznos lehet ugyanazt a fájlt többféle formátumban is tárolni, illetve ismerni az adott fájlformátum konvertálási lehetőségeit.
Az adatok rendszerezése
Az adatok gyors és egyszerű megtalálhatóságának kulcsa a hatékony rendszerezés. Egy megfelelően felépített mappa-struktúra alapja lehet, ha feltesszük magunknak a kérdést: hol keresnénk először egy adott fájlt? Meg kell határozni azt a rendezési elvet, amely leginkább illik ehhez a logikához. A mappák elnevezésére ugyanazok a tanácsok érvényesek, mint a fájlokra, a rendszerezésükre pedig a következő jó gyakorlatok léteznek:
- minden kutatásnak érdemes saját könyvtárat létrehozni
- nem tanácsos túl nagy, sok különböző fájlt tartalmazó mappákat létrehozni – ha van valamilyen rendezőelv (pl. dátum, vagy adatforrás), amely mentén további almappák hozhatók létre, akkor tegyük azt
- a túl mély struktúra is kerülendő – nem célszerű több, egymásba ágyazott mappát létrehozni, mint ahány fájlt ténylegesen elhelyezünk bennük (a sok kattintás nem csak sok idő, de el is veszhetünk az alkönyvtárak dzsungelében)
- ha megosztott mappákban dolgozunk, érdemes a hozzáférési jogosultságokra is nagyobb figyelmet fordítani – ha teljes mappát osztunk meg, akkor általában minden benne lévő fájl is megosztódik
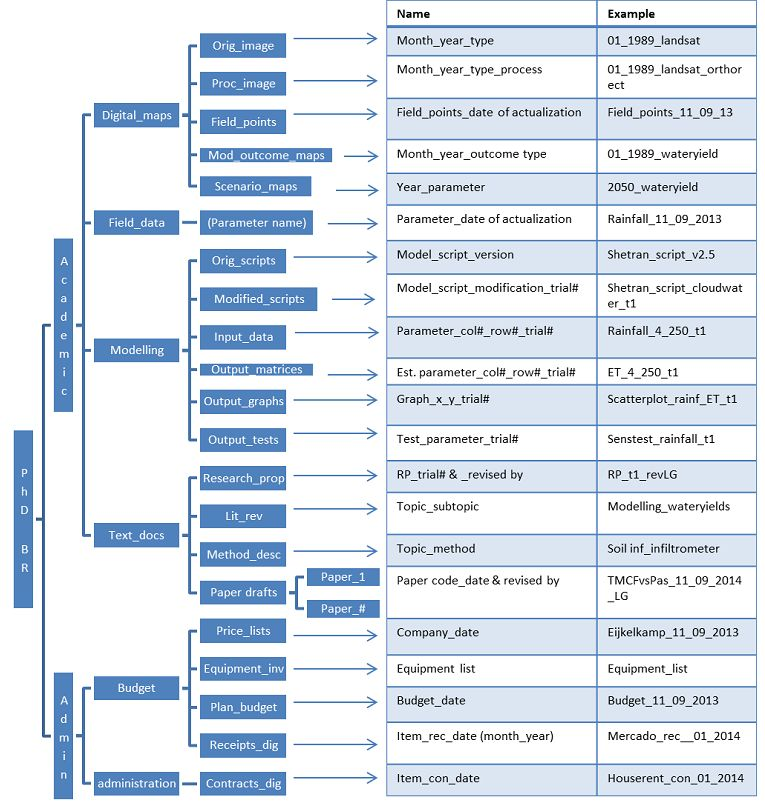
A következő ábra egy minta könyvtárat mutat be, melynek mappastruktúrája és az abban lévő fájlok elnevezése követendő példa lehet.
Dokumentáció és metaadatolás (readme/olvassel fájl)
A kutatási adatok kezelését nagyban megkönnyíti a pontos és részletes dokumentáció. Ezt többféle módon meg lehet valósítani, de a legegyszerűbben elkészíthető és használható módszer a readme (olvassel) fájl írása. Ez egy egyszerű, általában .txt formátumú szövegfájl, amely ideális esetben minden információt tartalmaz ahhoz, hogy a kutatási adatok reprodukálhatók legyenek.
A kutatás volumenétől függően lehet egyetlen átfogó readme fájlt írni akár az egész kutatáshoz, vagy több kisebbet az egyes adathalmazokhoz – vagy a két módszert ötvözni. Minden esetben ki kell derüljön, pontosan mire vonatkozik az adott readme (legegyszerűbb ezt a fájlnévben jelezni). Ajánlott minden, vagy legalább az ugyanahhoz a kutatáshoz tartozó readme fájlt ugyanolyan formában elkészíteni – legjobb, ha sablont alkalmazunk.
Egy jó readme fájlból a következő információk derülnek ki:
- fájlok elnevezésének magyarázata
- mappa-struktúra felépítésének elve
- munkafolyamat leírása: hogyan készült a nyers adatból kész, publikálható anyag?
- az adatokra vonatkozó információk aprólékos leírása: mik a mértékegységek, milyen rövidítések használatosak, melyik mezőben/cellában/sorban milyen adatok vannak, mik a változók, stb.
- fel kell tüntetni, ha van ismert hiba, következetlenség az adathalmazban, vagy valamilyen korlátozó tényező gátolja a használatát
- tartalmaz-e szenzitív információt
- a kész adathalmaz használatára vonatkozó információk: eredeti archiválási hely, hozzáférési jogosultságok, licenszek, újrahasznosítási módok és feltételek, stb.
- hogyan kell idézni
- kontakt személy elérhetősége, akihez fordulni lehet az adatokkal kapcsolatban
Az adattárolás eszközei
Fontos kiemelni, hogy a kutatási adatok elhelyezésének kérdése nem akkor lesz aktuális, amikor lezajlott a kutatás, és archiválni kellene a keletkezett adathalmazt, hanem már az első pillanattól fogva: amikor létrejön a nyers adat, érdemes megtervezni, hol és hogyan lenne célszerű azt tárolni a kutatás során. Az adattárolás módjának kiválasztásakor több szempontot is figyelembe kell venni.
A következő tényezők határozzák meg, mik lesznek a legoptimálisabb eszközök az egyes kutatási adathalmazok tárolására:
- mennyi ideig kell megőrizni az adatokat
- mekkora mennyiségű adatról van szó
- áll-e rendelkezésre anyagi erőforrás erre a célra
- hány ember dolgozik egyszerre ugyanazokkal a kutatási adatokkal
- a kutatásban résztvevők fizikailag ugyanott dolgoznak-e
- mennyire szenzitív adatokról van szó
Biztonsági mentés
Az adatvesztés elkerülése érdekében erősen ajánlott rendszeres biztonsági mentést végezni, lehetőleg több különböző helyen. Jó gyakorlat erre a “here+near+far” elv követése, különösen akkor, ha nagy mennyiségű, nehezen reprodukálható, értékes adattal dolgozunk. Ilyenkor három példányban mentjük az adatokat: az egyiket szerkesztjük, egy másikat valamilyen lokális adathordozóra (pl. külső merevlemez) mentjük, a harmadikat pedig valamilyen távoli szerveren vagy felhőben helyezzük el.
Források és hasznos linkek a témában:
- Quick & dirty data management: the 5 things you should absolutely be doing with your data now
https://www.dropbox.com/s/e8j0ttbd517yap2/QuickDirtyDataMgmt_Slides_MIT.pdf?dl=0) - Online research data seminars
https://www.youtube.com/playlist?list=PLWIsV2soJK-VaW7IhxYyyOwiamjVV_FuB - MIT Data Management Workshops
https://libraries.mit.edu/data-management/services/workshops - LIBER Webinars
https://www.youtube.com/playlist?list=PLHA3lUmrYM3sR0sdjTEED4ahsCO3GTx9w